Dokumentová AI sprint
Prototyp sémantického vyhledávání nad firemními dokumenty s jasným výstupem do tří týdnů — vhodné pro rychlé ověření hodnoty znalostní báze.
Více informací →COGNIVAULT · PRAHA KARLÍN
Vault 01 — 2026
CogniVault je pražské datové studio v Karlíně, které proměňuje firemní dokumenty, tabulky a obrazová data ve strukturované znalostní báze. Navrhujeme dokumentovou AI, hybridní sémantické vyhledávání, prediktivní modely a počítačové vidění s důrazem na auditovatelnost, GDPR a provoz v EU. Ceny uvádíme v Kč jako orientační rozsahy — každý projekt začíná inventarizací dat a definicí metrik úspěchu.
TREZOR ZNALOSTÍ
Mozaika datových vrstev


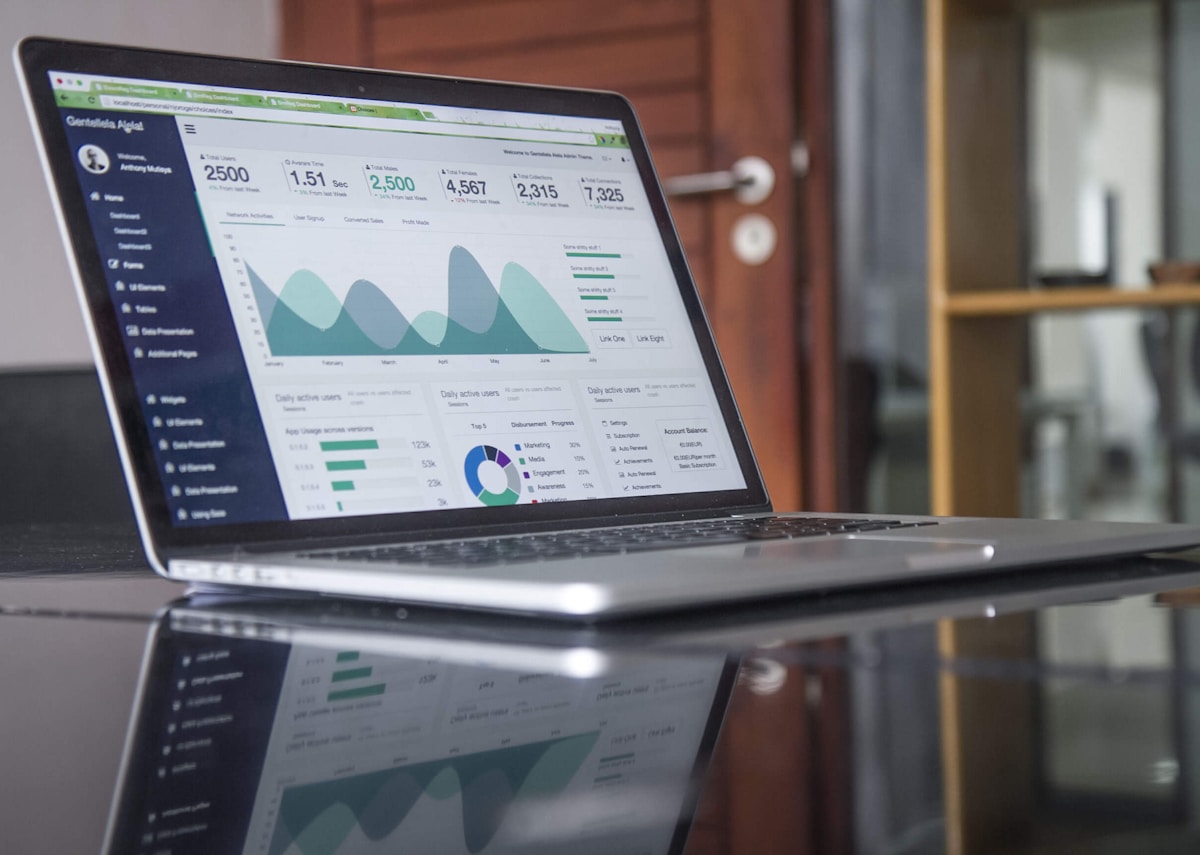
O COGNIVAULT
CogniVault s.r.o. sídlí v Praze 8 — Karlín na Pobřežní a specializuje se na datovou inteligenci pro B2B klienty v České republice i střední Evropě. Na rozdíl od univerzálních chatbotů stavíme znalostní systémy, které respektují vaše oprávnění, citlivost dokumentů a existující datové sklady. Každý projekt vedeme jako strukturovaný cyklus s inventarizací zdrojů, validací kvality indexace a dokumentací pro interní tým.
Pracujeme s datovými analytiky, produktovými manažery a IT architekty na celém cyklu — od mapování dokumentových toků přes sémantické indexování a prediktivní modely až po produkční nasazení s monitoringem kvality odpovědí. Naším cílem není prodat hotovou šablonu, ale postavit znalostní trezor, který odpovídá vašim datům a měřitelným cílům. Umělá inteligence u nás znamená konkrétní indexy, embedding modely a validované predikce — ne marketingový slogan.
CogniVault je datové studio pro znalostní systémy. Stavíme dokumentovou AI, sémantické vyhledávání, prediktivní analytiku, počítačové vidění a znalostní grafy nad vašimi existujícími daty. „Vault" znamená trezor znalostí — ne bankovní trezor, fyzické úložiště ani přeprodej BI nástrojů. Nejsme webová agentura, marketingové studio ani distributor cizího SaaS. Neposkytujeme online kurzy ani obecný IT outsourcing bez datového jádra. Pokud hledáte znalostní bázi nebo prediktivní analytiku v Karlíně, jste na správném místě.
OBLASTI DATOVÉ INTELIGENCE
Hybridní indexace PDF, smluv, technických manuálů a interních wiki s vektorovým vyhledáváním, rerankingem a citacemi zdrojů pro auditovatelné odpovědi.
Modely pro odhad poptávky, detekci anomálií, scoring rizik a predikci churnu nad vašimi historickými daty s validací na hold-out sadách a reportem přesnosti.
Klasifikace, detekce objektů a OCR pipeline pro skenované dokumenty, výrobní linky a kontrolu kvality s nasazením on-prem nebo v EU cloudu.
Entitní extrakce, vztahy mezi dokumenty a entitami a dotazování přes graf pro compliance, due diligence a komplexní doménové dotazy.
Každý projekt začíná strukturovaným auditem: mapujeme zdroje dokumentů, datové sklady, kvalitu metadat a integrační body v ERP, DMS nebo interních nástrojích. Bez kvalitního katalogu dat a jasné metriky relevance nedává smysl spouštět indexaci — proto klientům říkáme na rovinu, co je technicky proveditelné a co ne.
Ve fázi prototypu volíme architekturu podle specifik: hybridní sémantické vyhledávání pro znalostní báze, gradient boosting nebo neuronové sítě pro prediktivní analytiku, nebo CNN pipeline pro počítačové vidění. Validaci provádíme na vzorových dotazech klienta, hold-out sadách a s review boardem. Nasazení zahrnuje monitoring driftu dat, verzování indexů a dokumentaci pro váš interní tým.

PROGRAMY
Prototyp sémantického vyhledávání nad firemními dokumenty s jasným výstupem do tří týdnů — vhodné pro rychlé ověření hodnoty znalostní báze.
Více informací →Plnohodnotná znalostní báze s vektorovým a fulltextovým vyhledáváním, rerankingem a citacemi zdrojů.
Více informací →Modely pro odhad, scoring a detekci anomálií nad historickými daty s evaluací přesnosti.
Více informací →Klasifikace, detekce a OCR pipeline pro skenované dokumenty a výrobní procesy.
Více informací →Entitní extrakce a propojená data pro compliance a komplexní doménové dotazy.
Více informací →Dlouhodobá kapacita datového týmu pro iterace, údržbu indexů a rozšiřování znalostního portfolia.
Více informací →RYCHLÉ ODPOVĚDI
Ne. CogniVault je datové studio v Karlíně — stavíme znalostní systémy, dokumentovou AI, sémantické vyhledávání a prediktivní analytiku nad vašimi daty. „Vault" znamená trezor znalostí, ne bankovní trezor ani skladové úložiště. Nepřeprodáváme Power BI, Tableau ani jiné BI platformy. Doména .one označuje specializovanou znalostní službu — ne finanční produkt.
Typický prototyp sémantického vyhledávání dodáváme průměrně do čtrnácti pracovních dnů od dokončení inventarizace dat. Složitější znalostní grafy nebo prediktivní modely na rozsáhlých datech vyžadují delší harmonogram, který stanovíme před zahájením.
Pracujeme s vektorovými databázemi, embedding modely, PyTorch, scikit-learn, Neo4j pro znalostní grafy a cloudovými inference službami v EU. Volba stacku závisí na latenci, soukromí dat a provozních nákladech — včetně on-prem nasazení.
Domluvte si úvodní konzultaci s naším datovým týmem v Karlíně nebo na dálku.
Otevřít znalostní systémUpozornění: Relevance vyhledávání, přesnost predikcí a kvalita extrakce z dokumentů závisí na úplnosti dat, kvalitě metadat a specifikách use case. CogniVault navrhuje znalostní systémy na míru — výsledky se liší podle projektu; negarantujeme konkrétní metriky recall, precision ani regulatorní shodu. Uvedené ceny jsou orientační a potvrzujeme je v nabídce po úvodní analýze. Statistiky na webu jsou ilustrativní a anonymizované.